



Статья про языковые модели, кроме ChatGPT

В этой статье я решила сделать подборку моих статей про то, какие есть чат-боты помимо ChatGPT, чем они отличаются и для каких целей подходят. Как раз вы поймете, какие есть новые альтернативы ChatGPT, в том числе бесплатные, какие есть даже получше, которые уже видео полноценно смотрят, чего не умеет пока ChatGPT, когда есть смысл платить, а когда нет. Да и в целом разберетесь в последних новинках чат-ботов, которые как из рога изобилия вылетают каждую неделю и каждая типа "убийца ChatGPT", я постаралась по полочкам все разложить. Ну и заодно удобно-все в одном месте, как в учебнике)
1) Claude 3
Про Claude 3, а заодно еще к нему учебник по промптингу и сами промпты
2) Reka
3) LLaMa 3
4) Google Gemini 1.5 Pro
Про Gemini 1.5 Pro и обновление - ее научили понимать аудио
5) Command R+
Про Command R+ бесплатная хорошая нейросеть
Надеюсь, статья была для вас полезной, если вы хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни, то добро пожаловать в мой телеграм канал НейроProfit, где я рассказываю, как можно использовать нейросети для бизнеса.
Показать полностью

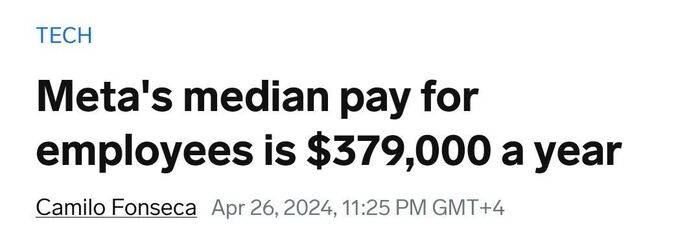
Стала известна медианная зарплата сотрудников Meta* — $379 000 в год
Согласно недавней отчетности, медианная зарплата сотрудника Meta в 2023 году составила более $379 000. Эта цифра значительно выше, чем в большинстве технологических компаний, однако сопоставима с конкурентами вроде Google и Amazon.
Примечание: Медианная зарплата — это середина общей шкалы зарплат. Учитывая, что в компании работает около 67 000 человек, разброс зарплат будет широким в обе стороны.
При этом, Meta продолжает сокращать штат и планирует потратить миллиарды на развитие искусственного интеллекта.
*Признана экстремистской и запрещена в РФ


Последние слова Макрона, тайны Суэцкого канала и невероятные дивы Гугла

📈 На Мосбирже наконец-то закончился 4-недельный рост! Но упало всё не слишком сильно: примерно на полпроцента. Пенсия и Хулинформатика в минимальном плюсе, а вот Бухло за счёт рывка Русагро (+9%) и Абрау (+3.5%) добавило 2% и 26 тысяч рублей (это новый хай за 1.5 года торговли и 48% годовых). Русагро я добрал в портфель ещё в субботу - потому что это был рабочий день; но что приятно, на Пенсии его уже было несколько лотов - стратегия работает! Хуже рынка (но несильно - всего -0,7%) сработало ЗЛО - там на 2.5% упало золотишко. В лидерах падения ТМК (-4%), МТС (-3%) и Фосагро (-2%), которые утянули Хулинвестиции на 22 тысячи рублей вниз. Софтлайн (+3.5%), Озон (+3%) и Астра (+2%) обеспечили новый хай по Хулинформатике (+4500 рублей) и 187 тыс. профита (29% годовых).
🇺🇸 После очередного предсказания краха S&P500 ломанулся аж на 3% вверх. Больше всего амерам помог Google своим объявлением дивидендов (и бай-бэком тоже). Вообще БигТех удивил профитами (подробнее чуть позже), а американский рынок в очередной раз не испугался инфляции - это ж лучшая неделя у S&P за полгода. Но в центре внимания сейчас студенческие протесты против еврейской доминации. Социалисты и про-палестинисты - это у них сейчас одно и то же (у нас, что характерно, леваки тоже обожают Палестину и ненавидят Израиль). Ну, типа, студенты протестуют против инвестиций, любой поддержки ну и вообще всего кошерного. Ну, кроме спонсоров, деканов и профессоров - ведь они, ну ты понел…
😱 Глава Минфина попросил "донастроить" систему налогообложения в России. Раньше это называлось ощипыванием.
🛶 Начиная с сегодняшнего дня побывать в Венеции станет немного дороже: 5 евро в день. На моей памяти это первый большой город, который ввёл налог на въезд туристов. Хотя вроде в Краснодарском крае такая же история, не? Кто отказался от поездки в Венецию, поднимите руку. Я вот как побывал там 25 лет назад, так больше и не собираюсь. Даже если б 5 евро мне доплачивали.
📘 Озон выкатил очередной отличный отчёт: убытки за 1 квартал 2024-го составили 13 млрд рублей. Думаете, много? Нет! Ведь в прошлых кварталах они составляли 22 и 18 млрд рублей! Налицо отрицательное падение!
🎦 Встроенный в TikTok магазин показывает новые рекорды продаж - речь о $4 млрд в год. Лучше всего продаётся косметика, пижамы и парфюмерия. Угадайте, чьего производства. Новая фишка - лакшери секонд-хенд, то есть поношенная роскошь. Ваще жесть, забанить бы его! Так, погодите…
🫴 Замминистра обороны арестован по обвинению в смехотворности взятки в 1 млн рублей.
🇫🇷 Лувр начал продавать билеты со встроенной йогой. За какие-то 30 евро можно будет раздвинуть ноги перед Мона Лизой - ну или Аполлоном, кому что. А Эммануэль Макрон заявил, что Евросоюзу угрожает экзистенциальный риск - ведь экономика в упадке, армия бессильна, а зависимость от США запредельна. “Хватит быть вассалами американцев”, - прямо так и сказал! Забавный такой.
🟢 Греф заявил, что год будет непростым, но Сбер заработает ещё больше денег. Наш слон! Берём! А, ну я уже взял.
🚗 Honda планирует вложить $11 млрд в фабрики на берегах Онтарио (это в Канаде), чтобы подстегнуть свои электромобили. Старт производства в 2028 году, компания планирует производить 240 тысяч электричек в год. Ну, если доживёт, конечно.
🇪🇬 165 лет назад - в конце апреля 1859 года - в Порт Саиде раздался первый удар кирки. Сейчас каждый год через Суэцкий канал проходит более 300 млн тонн груза - это десятки огромных судов каждый день. А помните, как 3 года назад какой-то лихач застрял на своём контейнеровозе поперёк канала? Будто вчера это было… Интересно, что строили канал французы и турки, но большее количество времени предприятием управлял кто? Конечно, Британия. Почти 100 лет она из Египта соки сосала.
🪟 Alphabet, Microsoft и Snap выдали отличные репорты за 1 квартал 23-го. Гугл объявил о первых в истории дивидендах, да ещё присовокупил $70 млрд к программе байбэка - акции тут же сделали самый мощный рывок аж за 10 лет. Microsoft тоже превозмогла прогнозы - там особенно всё хорошо с облачными сервисами. А у Снэпчата не только диковинная прибыль, но и дикий рост абонентской базы - жертв уже 422 млн. Ни одна из них мне неизвестна. Вы вообще когда-нибудь пользовались этим дерьмом? Ну и да, экстремисты из Меты провалили сейшен с дичайшими планами вливать миллиарды в ИИ. Ну, Паша им покажет как правильно деньги тратить.
💳 Klarna (это шведский рассрочный стартап типа “Халвы” или “Долями”) запартнёрилась с Uber. Теперь за такси можно платить не сразу, а типа в конце месяца. Ну и за доставку еды (Uber Eats) заодно. Работать оно будет пока только в Германии, США и Швеции, но вообще, если на такси и на доставку еды вам нужна рассрочка, у меня для вас плохие новости.
🇲🇩 Молдавский лей стоит 5 рублей 20 копеек. А год назад он стоил 4.5 рубля. А два года назад - 3.90. Не имей пять рублей, а имей молдавский лей! Интересно, куда делись шутки про строителей-молдаван? С начала год хулиндекс рубля упал к мировым валютам на 20.9%, а за два года - падал на на 2.8% в год.
Это были #хулиновости №18/2024 (151).
Показать полностью

LLaMA 3: Новая языковая модель от Meta

Компания Meta, владелец Facebook, Instagram, WhatsApp и Messenger, делает решительный шаг в мир искусственного интеллекта, интегрируя умных помощников в свои популярные приложения.
Этот амбициозный проект, основанный на новейшей языковой модели LLaMA 3, обещает революционизировать наше взаимодействие с социальными сетями и открыть новые возможности для коммуникации и получения информации.
Умные помощники на службе у пользователей
Новые ИИ-помощники будут доступны в лентах новостей, поисковых строках и чатах, предоставляя пользователям возможность получать помощь и информацию в режиме реального времени. Они смогут отвечать на вопросы, выполнять задачи и даже генерировать креативный контент.
Например, пользователь Instagram может спросить помощника о ближайших концертах, а пользователь WhatsApp может получить рекомендации по выбору ресторана. Возможности практически безграничны, и Meta уверена, что эти помощники станут незаменимыми инструментами для миллиардов людей по всему миру.
LLaMA 3: мощь и открытость
В основе новых помощников лежит LLaMA 3 – новейшая и самая мощная языковая модель Meta. Она способна генерировать текст, вести беседы и создавать изображения с высокой степенью точности и креативности.
Отличительной особенностью LLaMA 3 является ее открытый исходный код. Это означает, что любой разработчик может получить доступ к технологии и использовать ее для создания собственных продуктов и услуг. Такой подход способствует развитию ИИ-индустрии и позволяет независимым исследователям улучшать и совершенствовать модель.
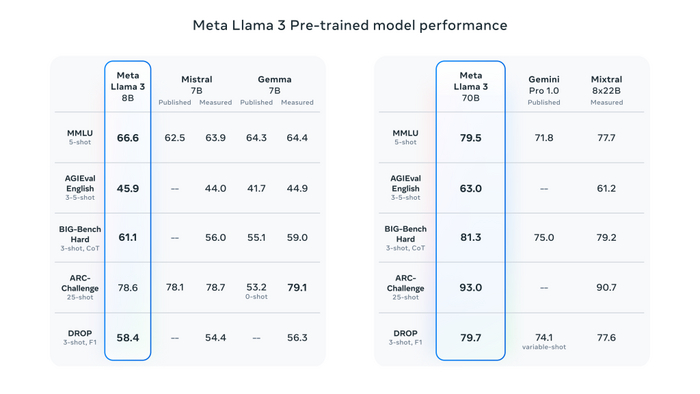
«Мы считаем, что это лучшие модели с открытым исходным кодом в своем классе», — заявили в Мета
Meta против конкурентов: гонка ИИ-вооружений
Внедрение ИИ-помощников является частью стратегии Meta по интеграции искусственного интеллекта во все свои продукты. Компания стремится не отставать от конкурентов, таких как Microsoft и Google, которые также активно развивают свои ИИ-технологии.
Microsoft интегрировала ChatGPT от OpenAI в свою поисковую систему Bing, а Google внедряет ИИ в такие сервисы, как Docs, Gmail и Google Search. Однако, Meta выделяется своей открытостью и масштабом, охватывая миллиарды пользователей по всему миру.
Вызовы и перспективы
Внедрение ИИ-помощников ставит перед Meta несколько важных вызовов. Компания должна обеспечить точность и надежность информации, предоставляемой помощниками, а также предотвратить возможность злоупотребления технологией. Кроме того, важно завоевать доверие пользователей и убедить их в полезности и безопасности новых инструментов.
Несмотря на эти вызовы, Meta уверена в успехе своего проекта. Компания считает, что ИИ-помощники станут неотъемлемой частью социальных сетей и изменят наше представление о коммуникации и доступе к информации.
Попробуй LLaMA 3
Показать полностью
1

Apple удалила Telegram, Signal, WhatsApp* и Threads* из китайского App Store по требованию местных властей
Источник информации-vc.ru

Те сослались на защиту национальной безопасности.
«Мы обязаны соблюдать законы стран, в которых работаем. Даже если мы с ними не согласны», — сообщили в Apple. Её позицию приводит WSJ. Остальные компании-разработчики публичных комментариев не давали.
Источник издания рассказал, что WhatsApp* и Threads* попросили удалить из-за «политического контента, содержащего спорные высказывания о главе Китая». В Apple это отрицают.
По словам Reuters, у удалённых приложений нет «широкой» аудитории в Китае. Там доминирует местный сервис WeChat. Facebook*, Instagram* и Messenger*, принадлежащие Meta*, по-прежнему доступны.
Как объясняют издания, китайцы могут получить доступ к большинству зарубежных приложений только через VPN, в обход «великого китайского файервола». Местное правительство относится к ним «с опаской», потому что там, помимо прочего, граждане могут прочитать новости, которые не прошли правительственную цензуру.
Российский депутат Антон Горелкин в ответ на новость заявил, что вместе с регулятором проработает вопрос об удалении сервисов Meta* из App Store в России.
Легальная возможность их установки не очень вяжется с тем, что доступ к ним официально блокируется. К тому же их исчезновение из App Store приведёт ещё к одному положительному эффекту: пользователи «яблочных» гаджетов будут реже использовать VPN-сервисы, о потенциальных и реальных рисках которых постоянно говорят эксперты.
Антон Горелкин, депутат
Правительство США тем временем обсуждает возможность принудить китайского разработчика TikTok продать сервис, чтобы продолжить работу в стране, иначе он столкнётся с блокировкой. По данным WSJ, китайские власти «дали сигнал» владельцу сервиса, что бан лучше продажи. А пользователи из Китая допустили, что США таким образом мстят за недоступность своих приложений в КНР.
*Meta, владеющая Facebook, Instagram, Messenger, WhatsApp и Threads, признана в России экстремистской организацией и запрещена.
Канал в Дзен-https://dzen.ru/id/63ee56f15a57ed4dd2d9c51f
Показать полностью


Фото реалистичный аватар в полный рост
Перевел через Elevenlabs , не знал, что они там несут)) Благо особо не заморачивался))
Meta* сделали нейросеть audio2photoreal, которая может сгенерировать видео с двигающимися аватарами по аудиофайлу. Достаточно загрузить аудио разговора и на выходе получаются реалистичные 3D-аватары.
Проект в открытом доступе на GitHub
Теперь уровень дипфейков шагнет вперед - аватары настолько реалистичны, что воспроизводят мимику, жесты и другие движения. Алгоритм способен даже распознать, когда в речи используется ухмылка, смех.
Подписывайтесь на ИИшница 🍳 - тут все самое интересное из мира новых технологий и нейросетей 🤖
Показать полностью

Жажда "цифровой крови": Как Google, OpenAI и Meta переступают черту ради развития ИИ

Технологические гиганты OpenAI, Google и Meta* в погоне за онлайн-данными для обучения своих новейших систем искусственного интеллекта готовы на всё: игнорировать корпоративные политики, менять собственные правила и даже обсуждать возможность обхода законов об авторском праве.
Одним из самых вопиющих примеров стали действия исследователей OpenAI в Сан-Франциско. Они разработали инструмент для транскрибирования видео с YouTube, чтобы собрать огромный массив разговорных текстов для развития ИИ. Некоторые сотрудники OpenAI выражали обеспокоенность тем, что такой шаг может нарушать правила YouTube, которые запрещают использовать видео платформы для "независимых" приложений. Однако в итоге команда во главе с президентом компании Грегом Брокманом, который лично участвовал в сборе данных, расшифровала более миллиона часов видео. Полученные тексты были загружены в GPT-4 - одну из самых мощных языковых моделей в мире, лежащую в основе чат-бота ChatGPT.
Эта история наглядно демонстрирует, насколько отчаянной стала гонка за цифровыми данными, необходимыми для прогресса ИИ. Ради заветных терабайтов информации технологические компании, включая OpenAI, Google и Meta*, готовы срезать углы, игнорировать внутренние политики и балансировать на грани закона. Расследование New York Times показало, что эти ИТ-гиганты всерьез обсуждали возможность обхода авторских прав ради пополнения своих баз данных.
В Meta*, которой принадлежат Facebook* и Instagram* , менеджеры, юристы и инженеры всерьез рассматривали вариант покупки издательства Simon & Schuster, чтобы заполучить большой объем книг. Они также обсуждали идею собирать защищенные авторским правом данные по всему интернету, даже если это грозило судебными исками. По их мнению, переговоры о лицензировании с издателями, авторами, музыкантами и новостной индустрией заняли бы слишком много времени.
Google, как и OpenAI, расшифровывал видео с YouTube для получения текстовых данных, потенциально нарушая авторские права создателей контента. Кроме того, в прошлом году компания расширила свои условия использования сервисов. Одной из причин этого изменения, по словам сотрудников отдела конфиденциальности и внутренних документов, стало желание получить возможность анализировать публично доступные файлы Google Docs, отзывы на Google Maps и другие онлайн-материалы для использования в своих ИИ-продуктах.

Эти примеры показывают, что новости, художественные произведения, посты на форумах, статьи из Википедии, компьютерные программы, фотографии, подкасты и фрагменты фильмов стали настоящей "цифровой кровью", питающей бурно развивающуюся индустрию искусственного интеллекта. Создание инновационных систем напрямую зависит от наличия достаточного объема данных для обучения ИИ мгновенной генерации текстов, изображений, звуков и видео, неотличимых от созданных человеком.
Объем данных имеет решающее значение. Ведущие чат-боты обучались на массивах цифровых текстов, включающих до трех триллионов слов - примерно вдвое больше, чем хранится в Бодлианской библиотеке Оксфордского университета, которая собирает рукописи с 1602 года. По словам исследователей ИИ, наиболее ценными являются высококачественные данные, такие как опубликованные книги и статьи, тщательно написанные и отредактированные профессионалами.
Долгие годы интернет с такими сайтами, как Википедия и Reddit, казался неиссякаемым источником данных. Но по мере развития ИИ технологические компании стали искать новые резервуары информации. Google и Meta, имеющие миллиарды пользователей, ежедневно генерирующих поисковые запросы и посты в соцсетях, во многом ограничены законами о конфиденциальности и собственными политиками в плане использования этого контента для обучения ИИ.
Ситуация становится критической. По прогнозам исследовательского института Epoch, уже к 2026 году технологические компании могут исчерпать все качественные данные, доступные в интернете. Гиганты индустрии потребляют информацию быстрее, чем она производится.
"Единственный практичный способ существования этих инструментов - это возможность обучать их на огромных объемах данных без необходимости лицензирования", - заявил Сай Дамл, юрист, представляющий интересы венчурной компании Andreessen Horowitz, в ходе публичной дискуссии об авторском праве. "Необходимый объем данных настолько огромен, что даже коллективное лицензирование не сможет решить проблему".
Технологические компании настолько жаждут новых данных, что некоторые из них разрабатывают "синтетическую" информацию. Речь идет не об органическом контенте, созданном людьми, а о текстах, изображениях и коде, генерируемых самими ИИ-моделями. Иными словами, системы учатся на том, что создают сами.

OpenAI заявила, что каждая ее ИИ-модель "имеет уникальный набор данных, который мы тщательно подбираем, чтобы улучшить их понимание мира и оставаться глобально конкурентоспособными в исследованиях". Google отметила, что ее модели "обучаются на некотором контенте YouTube" в рамках соглашений с авторами, и что компания не использует данные из офисных приложений вне экспериментальной программы. Meta* подчеркнула, что "агрессивно инвестировала" в интеграцию ИИ в свои сервисы и имеет миллиарды публично доступных изображений и видео из Instagram* и Facebook* для обучения своих моделей.
Для создателей контента растущее использование их произведений ИИ-компаниями стало поводом для исков о нарушении авторских прав и лицензировании. The New York Times подала в суд на OpenAI и Microsoft за использование защищенных авторским правом новостных статей без разрешения для обучения чат-ботов. OpenAI и Microsoft заявили, что использование материалов было "добросовестным" и разрешенным законом, поскольку оригинальные тексты были трансформированы для другой цели.
Более 10 000 торговых групп, авторов, компаний и других организаций направили свои комментарии по поводу использования творческих работ ИИ-моделями в Бюро авторских прав США - федеральное агентство, готовящее рекомендации по применению копирайта в эпоху ИИ.
Режиссер, актриса и писательница Джастин Бейтман заявила Бюро, что ИИ-модели используют контент, включая ее книги и фильмы, без разрешения и оплаты. "Это крупнейшая кража в истории Соединенных Штатов, точка", - подчеркнула она в интервью.
"Масштаб решает все": Как одна научная статья разожгла аппетит к данным

В январе 2020 года теоретический физик из Университета Джонса Хопкинса Джаред Каплан опубликовал новаторскую статью об ИИ, которая разожгла аппетит технологических гигантов к онлайн-данным. Его вывод был однозначен: чем больше информации, данных - "цифровой крови" ИИ-систем, будет использовано для обучения большой языковой модели (ключевой технологии чат-ботов), тем лучше будут её результаты. Подобно тому, как студент становится образованнее, прочитав больше книг, ИИ-алгоритмы могут точнее распознавать паттерны в тексте и давать более точные ответы, впитав больше данных.
"Все были поражены тем, что эти закономерности, которые мы называем "законами масштабирования", оказались столь же точными, как и те, что мы наблюдаем в астрономии или физике", - отметил доктор Каплан, опубликовавший статью в соавторстве с девятью исследователями OpenAI (сейчас он работает в ИИ-стартапе Anthropic).
Лозунг "Масштаб решает все" быстро стал боевым кличем для всей индустрии ИИ, ознаменовав начало безудержной гонки за данными, этой "цифровой кровью" для алгоритмов. Исследователи, которые раньше довольствовались относительно скромными публичными базами данных вроде Википедии или Common Crawl (архива из более чем 250 миллиардов веб-страниц, собираемого с 2007 года), осознали, что в новую эпоху этой информации катастрофически мало. Если до статьи Каплана датасеты с 30 000 фотографий с Flickr считались ценным ресурсом, то теперь ИИ-системам требовались терабайты текстов, изображений и другого "топлива" для развития.

Когда в ноябре 2020 года OpenAI представила GPT-3, эта модель была обучена на рекордном на тот момент объеме данных - около 300 миллиардов "токенов" (по сути, слов или частей слов). Впитав эту гору информации, система начала генерировать тексты с пугающей точностью, создавая блог-посты, стихи и даже компьютерные программы.
Гонка за "цифровой кровью" только начиналась. В 2022 году лаборатория DeepMind, принадлежащая Google, провела эксперимент с 400 ИИ-моделями, варьируя объем обучающих данных. Лучшие результаты показали системы, питавшиеся еще большим объемом информации, чем предсказывал Каплан. Модель Chinchilla "выпила" 1.4 триллиона токенов.
Но и этот рекорд вскоре был побит. В прошлом году китайские исследователи представили Skywork - ИИ-модель, обученную на 3.2 триллиона токенов из английских и китайских текстов. А Google анонсировала систему PaLM 2, проглотившую умопомрачительные 3.6 триллиона токенов - настоящее море данных.
Алгоритмы-вампиры вошли во вкус. И теперь уже ничто не могло остановить их ненасытную жажду информации, столь необходимой для развития ИИ...
Высасывая данные из YouTube: Как OpenAI переступила черту

В мае Сэм Альтман, генеральный директор OpenAI, признал, что запасы ценной информации в интернете скоро иссякнут под натиском ИИ-компаний, одержимых идеей масштаба. "Этот ресурс не бесконечен", - заявил он в своей речи на технологической конференции.
Альтман знал, о чем говорит. В OpenAI исследователи годами собирали данные, очищали их и скармливали ненасытным алгоритмам, превращая в топливо для обучения языковых моделей. Они выкачивали код с GitHub, поглощали гигантские базы шахматных партий, анализировали школьные тесты и домашние задания с сайта Quizlet. Но к концу 2021 года эти источники истощились, рассказали восемь человек, знакомых с ситуацией в компании.
OpenAI отчаянно нуждалась в новой информации для своего ИИ следующего поколения - GPT-4. Сотрудники обсуждали идеи транскрибировать подкасты, аудиокниги и видео с YouTube, создавать данные с нуля с помощью других ИИ-систем и даже покупать стартапы, накопившие большие объемы цифрового контента.
В итоге OpenAI создала инструмент распознавания речи Whisper, чтобы извлекать тексты из YouTube-роликов и подкастов, рассказали шесть человек. Однако правила YouTube запрещают не только использовать видео в "независимых" приложениях, но и получать доступ к контенту платформы "любыми автоматическими средствами (такими как роботы, ботнеты или скраперы)".
Сотрудники OpenAI понимали, что вступают в серую зону закона, но считали, что обучение ИИ на этих видео - это "добросовестное использование". Грег Брокман, президент компании, лично участвовал в сборе роликов с YouTube и скармливал их Whisper, став одним из создателей инструмента.
В прошлом году OpenAI выпустила GPT-4, модель, обученную на более чем миллионе часов видео, которые Whisper извлек с YouTube и превратил в бесценный ресурс для развития ИИ. Команду разработки GPT-4 возглавлял лично Брокман.

Некоторые сотрудники Google знали о практиках OpenAI, но не препятствовали им, так как сам Google использовал транскрипты YouTube-видео для обучения своих ИИ-моделей, рассказали два человека, знакомых с ситуацией. Такой подход мог нарушать авторские права создателей контента. Если бы Google попытался предъявить претензии OpenAI, это могло вызвать общественный резонанс и привести к скандалу вокруг методов самого техногиганта.
Алгоритмы продолжали безнаказанно высасывать данные из YouTube, превращая видео в топливо для развития ИИ, невзирая на правила платформы и вопросы этики. Жажда информации, разожженная гонкой за лидерство в сфере ИИ, оказалась сильнее угрызений совести и страха перед законом.
Как Google может использовать ваши данные: Изменения в политике конфиденциальности

В прошлом году Google внес изменения в свою политику конфиденциальности для бесплатных потребительских приложений. Согласно новой формулировке, компания использует информацию для улучшения сервисов, разработки новых продуктов, функций и технологий, которые приносят пользу как самим пользователям, так и обществу в целом.
Особое внимание было уделено использованию общедоступной информации для обучения языковых моделей ИИ и создания продуктов вроде Google Translate, чат-бота Bard и облачных ИИ-сервисов. Это дало Google гораздо более широкие возможности для сбора и анализа данных в целях развития искусственного интеллекта.
Однако эти изменения вызвали вопросы у членов команды по конфиденциальности. В августе двое из них обратились к менеджерам, чтобы прояснить, сможет ли Google начать использовать данные из бесплатных потребительских версий Google Docs, Google Sheets и Google Slides. По их словам, они не получили четких ответов.
Мэтт Брайант, представитель Google, заявил, что изменения в политике конфиденциальности были сделаны для ясности и что компания не использует информацию из Google Docs или связанных приложений для обучения языковых моделей "без явного разрешения" пользователей. Он уточнил, что речь идет о добровольной программе, которая позволяет пользователям тестировать экспериментальные функции.
"Мы не начали обучение на дополнительных типах данных на основе этого изменения формулировки", - подчеркнул Брайант.
Тем не менее, обновленная политика конфиденциальности дает Google гораздо больше пространства для маневра в плане использования пользовательских данных для развития ИИ. И хотя компания отрицает, что уже применяет информацию из своих офисных приложений для обучения языковых моделей, сама возможность такого использования вызывает вопросы у экспертов по конфиденциальности.

Ясно одно: в гонке за лидерство в сфере ИИ техногиганты готовы использовать все доступные ресурсы, и данные миллионов пользователей - слишком лакомый кусок, чтобы его игнорировать. Вопрос лишь в том, насколько далеко Google и другие компании готовы зайти в погоне за прогрессом, и сумеют ли они найти баланс между развитием технологий и защитой приватности своих клиентов.
Жажда данных и этические дилеммы: Как Meta* борется за лидерство в сфере ИИ

Марк Цукерберг, глава Meta, годами инвестировал в развитие искусственного интеллекта. Однако когда в 2022 году OpenAI выпустила свой чат-бот ChatGPT, Цукерберг внезапно осознал, что его компания отстает в гонке ИИ-вооружений. По словам трех нынешних и бывших сотрудников, он немедленно начал оказывать давление на своих подчиненных, требуя в кратчайшие сроки создать чат-бот, способный превзойти детище OpenAI. Руководители и инженеры получали звонки от босса в любое время дня и ночи.
Но уже к началу прошлого года Meta* столкнулась с той же проблемой, что и ее конкуренты: нехваткой данных для обучения ИИ. Ахмад Аль-Дахле, вице-президент компании по генеративному ИИ, сообщил руководству, что его команда использовала практически все доступные в интернете англоязычные книги, эссе, стихи и новостные статьи для разработки своей модели. Без расширения массива данных Meta* не сможет догнать ChatGPT, подчеркнул он.
В марте и апреле 2023 года лидеры бизнес-подразделений, инженеры и юристы Meta* практически ежедневно собирались, чтобы найти решение проблемы. Одни предлагали платить по 10 долларов за книгу, чтобы получить полные лицензионные права на новые произведения. Другие обсуждали возможность приобретения издательства Simon & Schuster, выпускающего книги таких авторов, как Стивен Кинг.
Но звучали и более радикальные идеи. Сотрудники говорили о том, что уже обобщали книги, эссе и другие произведения из интернета без разрешения правообладателей. Они всерьез рассматривали возможность и дальше "высасывать" защищенный авторским правом контент, даже если это грозило судебными исками. Один из юристов предупредил о "этических" проблемах, связанных с использованием интеллектуальной собственности без ведома и согласия авторов, но его слова были встречены гробовым молчанием.
Цукерберг требовал найти решение любой ценой. "Возможности, которые Марк хочет видеть в нашем продукте, мы сейчас просто не в состоянии обеспечить", - признал один из инженеров.
Несмотря на то, что Meta* управляет гигантскими социальными сетями, у компании не было достаточного объема пользовательских постов, пригодных для обучения ИИ. Многие пользователи Facebook* удаляли свои старые публикации, а сама платформа не располагала к созданию длинных текстов, подобных эссе. К тому же, после скандала 2018 года, связанного с передачей данных пользователей компании Cambridge Analytica, занимавшейся профилированием избирателей, Meta* была вынуждена ввести ограничения на использование информации о своих юзерах.
В недавнем обращении к инвесторам Цукерберг заявил, что миллиарды публично доступных видео и фотографий на Facebook* и Instagram* представляют собой массив данных, превосходящий Common Crawl (базу из сотен миллиардов веб-страниц, используемую для обучения ИИ). Но хватит ли этого, чтобы догнать и обогнать конкурентов?
В своих внутренних обсуждениях топ-менеджеры Meta* признавали, что OpenAI, судя по всему, использовала защищенные авторским правом материалы без разрешения. И хотя некоторые сотрудники поднимали вопросы об этичности такого подхода и справедливой оплате труда авторов, общий вывод был таков: Meta* может последовать этому "рыночному прецеденту", так как получение лицензий от множества правообладателей займет слишком много времени.

"Единственное, что отделяет нас от уровня ChatGPT - это буквально объем данных", - заявил на одном из совещаний Ник Грудин, вице-президент по глобальному партнерству и контенту. По его мнению, Meta* может опереться на решение суда по делу "Гильдия авторов против Google" от 2015 года. Тогда Google отстояла свое право сканировать, оцифровывать и каталогизировать книги в онлайн-базе, доказав, что использовала лишь фрагменты произведений, трансформируя их и создавая новый продукт, что подпадает под принцип "добросовестного использования".
Однако этические вопросы никуда не исчезли. Как рассказал один из сотрудников, даже на встрече с участием Криса Кокса, главного директора по продуктам Meta, никто не озаботился тем, насколько честно и правильно использовать творческий труд людей без их ведома и согласия.
Похоже, в Meta* решили идти по стопам OpenAI и Google, не считаясь с правами авторов. Гонка ИИ-вооружений набирает обороты, и все средства хороши в борьбе за лидерство. Но сумеет ли Марк Цукерберг найти баланс между жаждой прогресса и этикой? Или погоня за "цифровой кровью" для ИИ-моделей окончательно затмит в его империи все моральные ориентиры? Пока страсти вокруг ИИ накаляются, нам остается лишь гадать, какие еще границы готовы переступить техногиганты в стремлении к технологическому превосходству.
Искусственные данные: Выход из кризиса или путь в никуда?

В то время как Meta* и Google лихорадочно ищут новые источники "цифровой крови" для своих ненасытных ИИ-моделей, Сэм Альтман из OpenAI предлагает иной подход к решению надвигающегося кризиса данных.
По его мнению, которое он озвучил на майской конференции, компании вроде OpenAI в конечном итоге начнут обучать свои алгоритмы на текстах, сгенерированных самим ИИ - так называемых синтетических данных. Идея проста: если ИИ-модель способна создавать правдоподобные тексты, то она может сама производить дополнительную информацию для своего развития. Это позволит разработчикам создавать все более мощные системы, не завися от защищенных авторским правом материалов.
"Как только мы преодолеем горизонт событий синтетических данных, и модель станет достаточно умной, чтобы генерировать качественную информацию, все будет в порядке", - заявил Альтман.
Однако концепция синтетических данных, хотя и не нова, таит в себе немало подводных камней. Исследователи бьются над этой проблемой годами, но создать ИИ, способный эффективно обучать самого себя, оказалось очень непросто. Модели, которые учатся на собственных результатах, рискуют попасть в замкнутый круг, где они лишь усиливают свои причуды, ошибки и ограничения.
"Данные для этих систем - как тропа через джунгли, - говорит Джефф Клун, бывший исследователь OpenAI, ныне преподающий информатику в Университете Британской Колумбии. - Если они будут обучаться только на синтетической информации, то рискуют заблудиться в этих дебрях".
Чтобы избежать этой ловушки, OpenAI и другие компании изучают возможность совместной работы двух разных ИИ-моделей. Одна система генерирует данные, а вторая оценивает их качество, отделяя зерна от плевел. Впрочем, исследователи расходятся во мнениях, насколько эффективным окажется такой подход.
Но топ-менеджеры ИИ-индустрии уже мчатся вперед на всех парах. "Все должно быть в порядке", - уверенно заявляет Альтман.

Возможно, синтетические данные действительно помогут техногигантам преодолеть кризис "цифровой крови" и вывести ИИ на новый уровень. Но не приведет ли погоня за искусственным разумом, способным воспроизводить самого себя, к непредсказуемым последствиям? Не заблудятся ли наши ИИ-помощники в дебрях собственных алгоритмов, оторвавшись от реальности и потеряв связь с миром людей?
Цена прогресса в эпоху ИИ
Гонка за "цифровой кровью" и стремление к созданию все более мощных ИИ-систем ставит перед человечеством непростые вопросы. Готовы ли мы пожертвовать приватностью, авторскими правами и этическими принципами ради технологического прогресса? Сможем ли мы сохранить контроль над своими творениями, когда они начнут воспроизводить сами себя? Опасность потерять ориентиры в цифровых джунглях искусственного интеллекта еще никогда не была столь реальной. Но одно можно сказать наверняка: мир уже никогда не будет прежним. Мы стоим на пороге новой эры, где границы между человеческим и машинным интеллектом становятся все более размытыми. И только от нас зависит, сумеем ли мы направить эту революцию в нужное русло и извлечь из нее максимум пользы для всего человечества.

Причем каждый из нас может внести свой вклад в эту дискуссию - делитесь своими мыслями в комментариях и ставьте оценки этой статье, ведь именно наши с вами комментарии повлияют в конечном счете на обучение какой-нибудь языковой модели.
Я рассказываю больше о нейросетях и делюсь иллюстрациями у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке.
*Meta и соцсети компании Facebook и Instagram признаны экстремистскими и запрещены в РФ.
Показать полностью
13